

When everyone’s losing it.
When everyone’s losing it.
The 5th skull early Homo skull from the site of Dmanisi was announced last week. The skull was discovered nearly 10 years ago, but is finally (and very comprehensively) published in Science (Lordkipanidze et al. 2013). The ‘new’ D4500 cranium goes with the massive D2600 mandible, making this the earliest and most complete skull of Homo that I know of. It’s really a remarkable specimen, for a number of reasons beyond its age and completeness. I’ve been busy traveling, teaching and writing lately, so I haven’t yet gotten to pore over the details as much as I’d like. So I hope to sporadically post thoughts on this badass new skull as they come to me. In the mean time, several of what I’d consider the top biology/anthropology blogs*** have discussed the skull, so do check those out if you haven’t already.
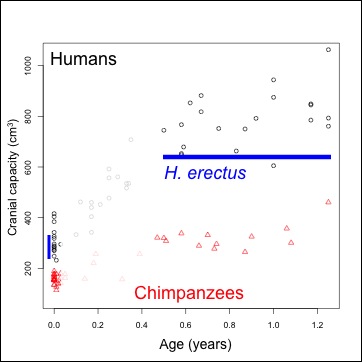
The first thing I noted about D4500 is its small brain size, estimated at a mere 546 cubic centimeters. For perspective, D4500 is the green point in the following plot showing brain size in early human evolution:

Endocranial volume for various fossil hominin fossils. 1: Australopithecus afarensis, africanus & boisei; 2: Dmanisi specimens; 3: “habilines” 4: early African Homo erectus; 5: Indonesian and Chinese Homo erectus. D4500 is green with envy.
I got to see (but not study) the cranium a few years ago when I was helping with the Dmanisi Paleoanthropology field school, and I remember noting just how “robust” the specimen was – big mastoid processes, prominent and thick brow ridge, huge attachments for the neck muscles. In humans, and presumably our fossil forebears, these features are more developed in males than females, and so presumably D4500 was a male (consistent with the huge, associated D2600 mandible). In many primates, and 4 to ~1 mya hominins so far as we can tell, males are larger than females. So it is surprising that a robust probable male cranium is in fact not only the smallest in the Dmanisi sample, but also at the low end of early African Homo (i.e. habilis or rudolfensis), comparable to the largest australopiths. Of course, the only other faces known from Dmanisi are either not fully grown (D2700 and D2282) or old and decrepit (D3444), so perhaps the larger-brained specimens would have been at least as robust as D4500. An untestable hypothesis!
The new skull really highlights the overlap, or continuous variation between later australopiths and early Homo known also from eastern Africa. In association with the postcranial remains known from Dmanisi, the authors the paper posit that early Homo may have been distinguished from Australopithecus not so much in brain size as in body size. We could probably add body shape (limb proportions) and tool use to that list of distinguishing features, and to be sure there are Oldowan tools and small but human-like body size and shape indicated by postcrania at Dmanisi. But then, evidence for body proportions and for/against tool use in Australopithecus, especially later in the record, is somewhat equivocal…
More thoughts to follow.
*** https://blogs.wellesley.edu/vanarsdale/2013/10/17/uncategorized/the-new-wonderful-dmanisi-skull/; http://johnhawks.net/weblog/fossils/lower/dmanisi/d4500-lordkipanidze-2013.html; http://ecodevoevo.blogspot.com/2013/10/how-many-human-species-are-there-is-it.html
Reference: David Lordkipanidze, Marcia S. Ponce de León, Ann Margvelashvili, Yoel Rak, G. Philip Rightmire, Abesalom Vekua, and Christoph P. E. Zollikofer. 2013. A Complete Skull from Dmanisi, Georgia, and the Evolutionary Biology of Early Homo. Science: 342 (6156), 326-331.
 |
| The Mojokerto calvaria. You’re looking at the left side of the skull: the face would be to the left. Check it out in 3D here. |
A few months ago I posted an abridged version of the presentation I gave at this year’s meetings of the American Association of Physical Anthropologists, about brain growth in Homo erectus. This study, co-authored with Jeremy DeSilva, adopts a novel approach (see “Methods” in that earlier post) to analyze the Mojokerto fossil (right). The specimen is the only H. erectus non-adult complete enough to get a decent estimate of brain size (or rather, the overall volume of the brain case) – probably 630 to 660 cubic centimeters (Coqueugniot et al. 2004; Balzeau et al., 2004). So to study brain growth in the extinct species, we just have to connect a range of estimated brain sizes at birth (around 290 cubic centimeters, based on predictive equations by DeSilva and Lesnik, 2008) to that of Mojokerto. But, the speed of brain growth implied by this comparison depends on how old poor Mojokerto was when s/he died.
Most recently, Hélen Coqueugniot and colleagues (2004) used CT scans of the fossil to examine the fusion of its various bones, to suggest the poor kid died between six months to 1.5 years, if not even younger. Antoine Balzeau and team (2005) also studied scans of the fossil, and their analysis of its virtual endocast presented conflicting age estimates, but they argued the poor kid was probably no older than 4 years. Earlier studies had suggested the kid was up to 8 years. Now, for my previous post/conference presentation, we assumed the Coqueugniot estimate was correct – but what if we consider a full range of ages for Mojokerto, from 0.03-6.00 years?
 |
| Brain size, relative to newborns’ values, at different ages in humans (black circles) and chimpanzees (red triangles). Homo erectus median and mean are the thick solid and dashed blue lines, respectively, and the 90% and 95% confidence intervals are indicated by the thinner, dotted blue lines. Data are the same as in the previous post. |
The plot above depicts brain size relative to newborns: each circle (humans) and triangle (chimpanzees) represents the proportional size difference between a newborn (less than 1 week) and an older individual, up to 6 years. Obviously, relative brain size gets bigger in humans and chimpanzees over time. Interestingly, even though humans and chimps have very different brain sizes, the proportional brain size changes overlap a lot between species, especially at younger ages. Ah, the joys of cross-sectional samples.
But what’s especially interesting here are the blue lines on the graph, indicating estimates of proportional size change in Homo erectus, assuming Mojokerto’s skull could hold 630 cc of delicious brain matter, and that the species’ skulls at birth could hold about 290 cc, give or take several cc. The thick solid and dashed lines just above 2 on the y-axis are the mean and median of our estimates – Mojokerto’s brain averages around 2.2 times larger than predicted newborns. Such a proportion is most likely to be found in humans between 6 months to a year of age, and in chimpanzees between around 6 months and 2 years. The confidence intervals, the highest and lowest bounds of our estimates for Homo erectus proportional size change, are the thinner dashed lines on the graph. They help us constrain our estimates, and further suggest that the proportional difference found for H. erectus is most likely to be found in either chimpanzees or humans around 1 year of age – just like Coqueugniot and colleagues predicted!!!
Thus, independent evidence – brain size of Mojokerto and estimated brain size at birth in Homo erectus – corroborates a previously estimated age at death for the Mojokerto fossil, the poor little Homo erectus baby. This further supports our estimates of brain growth rates in this species, as described in the previous post.
![]() So to summarize, fairly scant fossil evidence compared with larger extant species samples using randomization statistics, argue for high, human-like infant brain growth rates in Homo erectus by around 1 million years ago. Our ancestors were badasses.
So to summarize, fairly scant fossil evidence compared with larger extant species samples using randomization statistics, argue for high, human-like infant brain growth rates in Homo erectus by around 1 million years ago. Our ancestors were badasses.
Remember, if you want the R code I wrote to do this study, just lemme know!
Those references
Balzeau A, Grimaud-Hervé D, & Jacob T (2005). Internal cranial features of the Mojokerto child fossil (East Java, Indonesia). Journal of human evolution, 48 (6), 535-53 PMID: 15927659
Coqueugniot H, Hublin JJ, Veillon F, Houët F, & Jacob T (2004). Early brain growth in Homo erectus and implications for cognitive ability. Nature, 431 (7006), 299-302 PMID: 15372030
DeSilva JM, & Lesnik JJ (2008). Brain size at birth throughout human evolution: a new method for estimating neonatal brain size in hominins. Journal of human evolution, 55 (6), 1064-74 PMID: 18789811
The annual meetings of the American Association of Physical Anthropologists were going on all last week, and I gave my first talk before the Association (co-authored with Jeremy DeSilva). The talk focused on using resampling methods and the abysmal human fossil record to assess whether human-like brain size growth rates were present in our >1 mya ancestor Homo erectus. This is something I’ve actually been sitting on for a while, and wanted to wait til after the talk to post for all to see. I haven’t written this up yet for publication, but before then I’d like to briefly share the results here.
Background: Humans’ large brains are critical for giving us our unique capabilities such as language and culture. We achieve these large (both absolutely, and relative to our body size) brains by having really high brain growth rates across several years; most notable are exceptionally high, “fetal-like” rates during the first 1-2 years of life. Thus, rapid brain growth shortly after birth is a key aspect of human uniqueness – but how ancient is this strategy?
Materials: We can plot brain size at birth in humans and chimpanzees (our closest living relatives) to visualize what makes humans stand out (Figure 1).
 |
| Figure 1. Brain size (volume) at given ages. Humans=black, chimpanzees=red. Ranges of brain size at birth, and the chronological age of the Mojokerto fossil, in blue. |
Human data come from Cogueugniot and Hublin (2012), and chimpanzees from Herndon et al. (1999) and Neubauer et al. (2012). The earliest fossil evidence able to address this question comes from Homo erectus. Because of the tight relationship between newborn and adult brain size (DeSilva and Lesnik 2008), we can use adult Homo erectus brain volumes (n=10, mean = 916.5 cm^3) to predict that of the species’ newborns: mean = 288.9 cm^3, sd = 17.1). An almost-recent analysis of the Mojokerto Homo erectus infant calvaria suggests a size of 663 cm^3 and an age of 0.5-1.25 years (Coqueugniot et al. 2004; this study actually suggests an oldest age of 1.5 years, but the chimpanzee sample here requires us to limit the study to no more than 1.25 years). Because we have a H. erectus fossil less than 2 years of age, and we can estimate brain size at birth, we can indirectly assess early brain growth in this species.
Methods: Resampling statistics allow inferences about brain growth rates in this extinct species, incorporating the uncertainty in both brain size at birth, and in the chronological age of the Mojokerto fossil. We thus ask of each species, what growth rates are necessary to grow one of the newborn brain sizes to any infant between 0.5-1.25 years? And from there, we compare these resampled growth rates (or rather, ‘pseudo-velocities’) between species – is H. erectus more similar to modern humans or chimpanzees? There are 294 unique newborn-infant comparisons for humans and 240 for the chimpanzee sample. We therefore compare these empirical newborn-infant pairs from extant species to 7500 resampled H. erectus pairs, randomly selecting a newborn H. erectus size based on the parameters above, and randomly selecting an age from 0.5-1.25 years for the Mojokerto specimen. This procedure is used to compare both absolute size change (the difference between an infant and a newborn size, in cm^3/year), and and proportional size change (infant/newborn size).
Results: Humans’ high early brain growth rates after birth are reflected in the ‘pseudovelocity curve’ (Figure 2). Chimps have a similar pattern of faster rates earlier on, but these are ultimately lower than humans’. Using the Mojokerto infant’s brain size (and it’s probable ages) and the likely range of H. erectus neonatal brain sizes (mean = 288, sd = 17), it is fairly clear that H. erectus achieved its infant brain size with high, human-like rates in brain volume increase.
 |
| Figure 2. Brain size growth rates (‘pseudo-velocity’) at given ages. Humans=black, chimpanzees=red, and Homo erectus,=blue. |
However, if we look at proportional size change, the factor by which brain size increases from birth to a given age, we see a great deal of overlap both between age groups within a species, and between different species. Cross-sectional data create a great deal of overlap in implied proportional size change between ages within a species; it is easier to consider proportional size change between taxa, conflating ages, then (Figure 3). Humans show a massive amount of variation in potential growth rates from birth to 0.5-1.25 years, and chimpanzees also show a great deal of variation, albeit generally lower than in the human sample. Relative growth rates in Homo erectus are intermediate between the two extant species.
 |
| Figure 3. Proportional brain size increase (infant/newborn size). |
Significance: Brain size growth shortly after birth is critical for humans’ adaptative strategy: growing a large brain requires a lot of energy and parental (especially maternal) investment (Leigh 2004). Plus, in humans this rapid increase may correspond with the creation of innumerable white-matter connections between regions of the brain (Sakai et al. 2012), important for cognition or intelligence. The H. erectus fossil record (1 infant and 10 adults) provides a limited view into this developmental period. However, comparative data on extant animals (e.g. brain sizes from birth to adulthood), coupled with resampling statistics, allow inferences to be made about brain growth rates in H. erectus over 1 million years ago.
Assuming the Mojokerto H. erectus infant is accurately aged (Coqueugniot et al. 2004), and that Homo erectus followed the same neonatal-adult scaling relationship as other apes and monkeys (DeSilva and Lesnik 2008), it is likely that H. erectus had human-like rates of absolute brain size growth. Thus, the energetic and parental requirements to raise such brainy babies, seen in modern humans, may have been present in Homo erectus some 1.5 million years ago or so. This may also imply rapid white-matter proliferation (i.e. neural connections) in this species, suggesting an intellectually (i.e. socially or linguistically) stimulating infancy and childhood in this species. At the same time, relative brain size growth appears to scale with overall brain size: larger brains require proportionally higher growth rates. This is in line with studies suggesting that in many ways, the human brain is a scaled-up version of other primates’ (e.g. Herculano-Houzel 2012).
![]()
This study was made possible with published data, and the free statistical programming language R.
Contact me if you want the R code used for this analysis, I’m glad to share it!
References
Coqueugniot H, Hublin JJ, Veillon F, Houët F, & Jacob T (2004). Early brain growth in Homo erectus and implications for cognitive ability. Nature, 431 (7006), 299-302 PMID: 15372030
Coqueugniot H, & Hublin JJ (2012). Age-related changes of digital endocranial volume during human ontogeny: results from an osteological reference collection. American journal of physical anthropology, 147 (2), 312-8 PMID: 22190338
DeSilva JM, & Lesnik JJ (2008). Brain size at birth throughout human evolution: a new method for estimating neonatal brain size in hominins. Journal of human evolution, 55 (6), 1064-74 PMID: 18789811
Herculano-Houzel S (2012). The remarkable, yet not extraordinary, human brain as a scaled-up primate brain and its associated cost. Proceedings of the National Academy of Sciences of the United States of America, 109 Suppl 1, 10661-8 PMID: 22723358
Herndon JG, Tigges J, Anderson DC, Klumpp SA, & McClure HM (1999). Brain weight throughout the life span of the chimpanzee. The Journal of comparative neurology, 409 (4), 567-72 PMID: 10376740
Leigh SR (2004). Brain growth, life history, and cognition in primate and human evolution. American journal of primatology, 62 (3), 139-64 PMID: 15027089
Neubauer, S., Gunz, P., Schwarz, U., Hublin, J., & Boesch, C. (2012). Brief communication: Endocranial volumes in an ontogenetic sample of chimpanzees from the taï forest national park, ivory coast American Journal of Physical Anthropology, 147 (2), 319-325 DOI: 10.1002/ajpa.21641
Sakai T, Matsui M, Mikami A, Malkova L, Hamada Y, Tomonaga M, Suzuki J, Tanaka M, Miyabe-Nishiwaki T, Makishima H, Nakatsukasa M, & Matsuzawa T (2012). Developmental patterns of chimpanzee cerebral tissues provide important clues for understanding the remarkable enlargement of the human brain. Proceedings. Biological sciences / The Royal Society, 280 (1753) PMID: 23256194
Herman Pontzer and buddies just published a brief analysis of fine-scale tooth wear in the Dmanisi Homo erectus specimens.
Teeth are useful as hell in life. Humans’ teeth are critical not only for eating, sporting a sexy smile, and biting people, but also for speech and song (“f,” “th” and “v” sounds). Some parents even harvest their childrens’ exfoliated baby teeth. The things we do with teeth.
Teeth are also really useful for studying long-dead people and animals – teeth may preserve pretty well for millions of years, they can be used to estimate an individual’s age-at-death, and their shape and composition can be used to learn about diet. In a vile act of revenge, the food that sustains us also scrawls its Nom Hancock into the surfaces of our teeth. So, scientists can study the microscopic marks (= “microwear”) on tooth surfaces to see what kinds of foods were eaten shortly before death. Peter Ungar, an author of the current paper, has done a lot of work here, and his website is worth checking out if you’re interested in learning more. Microwear can’t really tell you exactly what an animal was eating, but can tell you whether the animal mostly ate grasses, leaves, hard objects like nuts, and so forth.
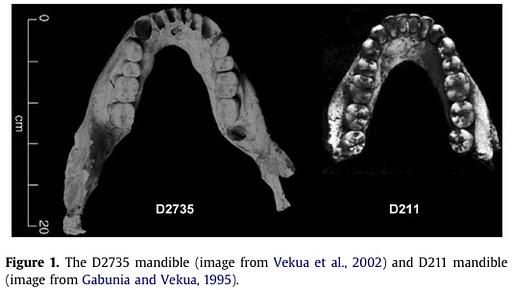 So Pontzer and colleagues examined the microwear on some of the lower molars of the youngest individuals from the nearly 1.8 million year old Homo erectus group from Dmanisi in the Republic of Georgia . To the left is a picture of the jaws, from the paper (from another paper. how meta). The microwear patterns of these badass early humans fit cozily within the variation exhibited by other Homo erectus specimens.
So Pontzer and colleagues examined the microwear on some of the lower molars of the youngest individuals from the nearly 1.8 million year old Homo erectus group from Dmanisi in the Republic of Georgia . To the left is a picture of the jaws, from the paper (from another paper. how meta). The microwear patterns of these badass early humans fit cozily within the variation exhibited by other Homo erectus specimens.
Microwear in Homo erectus is pretty variable, but still rather distinct from other fossil groups like robust Australopithecus, and a little less distinct from their putative ancestor H. habilis. This suggests that something special about Homo erectus was the species’ great dietary breadth – Homo erectus‘ key to geographic and evolutionary success might not have been the adoption of a specific dietary resource, but rather the ability to utilize a wide range of food resources. Atkins diet be damned. What’s neat is that the Dmanisi hominids, though kind of primitive (Australopithecus-like) in terms of brain size and some aspects of skull shape, nevertheless demonstrated key behaviors of H. erectus, namely geographic expansion (Dmanisi is the oldest reliably-dated hominid site outside Africa), and dietary flexibility. This really suggests the success of our ancestors was due to some behavioral innovation, aside from advances in stone tool technology.

Now, these Dmanisi H. erectus folks’ teeth wore like other H. erectus, and it would be reasonable to infer that this is because they ate similar foods. This makes it all the more mysterious that the other Dmanisi jaws, from older adults, have teeth completely worn to smithereens. Most notably, D3444 and D3900 (left, from here) comprise the skull of an individual who was missing all their teeth, except maybe a lower canine – the earliest example of edentulism in the human fossil record (Lordkipanidze et al. 2005). A very large mandible, D2600, with teeth so worn that the pearly-white first-molar crowns were gone and the internal pulp cavity (and nerve) were exposed. (Interestingly, D2600 is so large that some researchers initially argued it represented a different species from the other jaws – yet Adam Van Arsdale presented evidence that this extreme tooth wear may actually be responsible for making jaws relatively taller in early humans).
So what’s curious is why the older Dmanisi hominids should show such an extreme amount of tooth wear compared to other H. erectus, but microwear on the young suggests their diet was the same (that is, just as diverse in texture) as others in the species. Was Dmanisi-level tooth wear (and tooth loss) comparable to other H. erectus, and we just happen not to have found them at other sites? (KNM-ER 730 from Kenya is the next-most worn early Homo that next comes to mind) Is there another aspect of diet we don’t know about, that caused the Dmanisi teeth to wear especially quickly? Or were these early Homo from Dmanisi actually living longer than other H. erectus? I suspect the second is more likely, but that’s a hypothesis that remains to be tested.
Proof that paleoanthropology is cool: the Dmanisi hominids (Mzia is the girl on the left and Zezva the dude on the right), tagged onto a storefront in downtown Tbilisi.


A paper, given at this year’s Physical Anthropology meetings, was just published online in the Journal of Human Evolution, with a re-evaluation of the height and possible growth pattern of a subadult skeleton of Homo erectus (KNM-WT 15000, aka “Nariokotome boy,” aka “Stripling youth”). When initially described, it was estimated that this young chap would gave grown to be around 6 feet tall. However, controversy around the skeleton’s age at death and probable growth pattern have made this quite a contentious topic. In the recent paper, Ronda Graves and colleagues used a South African human growth pattern and a pattern from “naturally-reared captive” chimpanzees to devise a series of intermediate growth patterns that might have characterized H. erectus. Using the pattern they felt most likely reflected the Nariokotome skeleton’s estimated life history parameters, the authors estimate the potential adult height of the youth to have been closer to about 5′ 4″.

{kind=link}
{kind=link}